搜索到
182
篇与
的结果
-
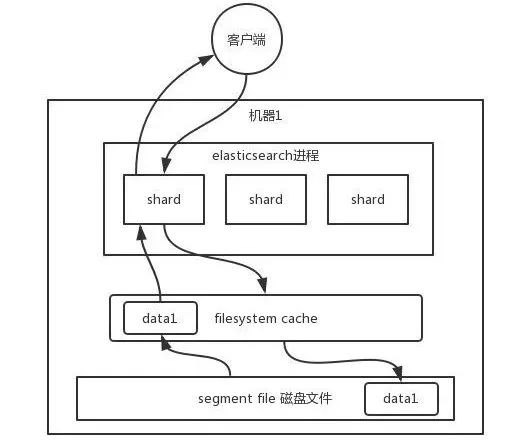
 大数据量搜索解决方案-ThinkPHP5+Elasticsearch搜索引擎 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎。当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。实时分析的分布式搜索引擎。可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。你往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去。整个过程,如下图所示:ES 的搜索引擎严重依赖于底层的 Filesystem Cache,你如果给 Filesystem Cache 更多的内存,尽量让内存可以容纳所有的 IDX Segment File 索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。提升性能的小技巧:仅在 ES 中就存少量的数据,无关检索的数据使用HBase等数据库存储,让Filesystem Cache可以容纳更多的数据量。数据预热,经常会有人访问的数据,每隔一段时间,就提前访问一下,让数据进入 Filesystem Cache 里面去。1、安装Elastaic官网下载地址:https://www.elastic.co/downloads/elasticsearch# 解压到非root目录,运行时使用非root账号且必须安装java环境yum install javawget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gztar zxvf elasticsearch-6.2.3.tar.gzuseradd elasticsearchpassword elasticsearchchown elasticsearch:elasticsearch elasticsearch-6.2.3cd elasticsearch-6.2.3nohup ./bin/elasticsearch & #设置成常驻进程php扩展库引入 composer.json{ "require": { "elasticsearch/elasticsearch": "~6.0" } }Client使用示例:prepare($sql); $query->execute(); $lists = $query->fetchAll(); print_r($lists); } catch (Exception $e) { echo $e->getMessage(); } $client = ClientBuilder::create()->build(); foreach ($lists as $row) { $params = [ 'body' => [ 'id' => $row['id'], 'title' => $row['title'], 'content' => $row['content'] ], 'id' => 'article_' . $row['id'], 'index' => 'articles_index', 'type' => 'articles_type' ]; $client->index($params); } } /* * 功能:获取索引 * return */ public function getIndex(){ $client = ClientBuilder::create()->build(); $params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'article_1' ]; $res = $client->get($params); print_r($res); } /* * 功能:从索引中删除文档 * return */ public function delIndex(){ $client = ClientBuilder::create()->build(); $params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'article_1' ]; $res = $client->delete($params); print_r($res); } /* * 功能:设置索引 * return */ public function createIndex(){ $client = ClientBuilder::create()->build(); $params['index'] = 'articles_index'; $params['body']['settings']['number_of_shards'] = 2; $params['body']['settings']['number_of_replicas'] = 0; $client->indices()->create($params); } /* * 功能:查询条件 * return */ public function search(){ $client = ClientBuilder::create()->build(); $params = [ 'index' => 'articles_index', 'type' => 'articles_type', ]; //多字段匹配 // $params['body']['query']['multi_match']['query'] = '我的宝马发动机多少'; // $params['body']['query']['multi_match']['fields'] = ["title","content"]; // $params['body']['query']['multi_match']['type'] ="most_fields"; // most_fields 多字段匹配度更高 best_fields 完全匹配占比更高 // // //单个字段匹配 // $params['body']['query']['match']['content'] = '我的宝马多少马力'; //完全匹配 // $params['body']['query']['match_phrase']['content'] = '我的宝马多少马力'; //联合搜索 must,should,must_not $params['body']['query']["bool"]['must']["match"]['content'] = "宝马"; $params['body']['query']["bool"]['must_not']["match"]['title'] = "宝马"; $res = $client->search($params); print_r($res); } }
大数据量搜索解决方案-ThinkPHP5+Elasticsearch搜索引擎 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎。当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。实时分析的分布式搜索引擎。可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。你往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去。整个过程,如下图所示:ES 的搜索引擎严重依赖于底层的 Filesystem Cache,你如果给 Filesystem Cache 更多的内存,尽量让内存可以容纳所有的 IDX Segment File 索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。提升性能的小技巧:仅在 ES 中就存少量的数据,无关检索的数据使用HBase等数据库存储,让Filesystem Cache可以容纳更多的数据量。数据预热,经常会有人访问的数据,每隔一段时间,就提前访问一下,让数据进入 Filesystem Cache 里面去。1、安装Elastaic官网下载地址:https://www.elastic.co/downloads/elasticsearch# 解压到非root目录,运行时使用非root账号且必须安装java环境yum install javawget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gztar zxvf elasticsearch-6.2.3.tar.gzuseradd elasticsearchpassword elasticsearchchown elasticsearch:elasticsearch elasticsearch-6.2.3cd elasticsearch-6.2.3nohup ./bin/elasticsearch & #设置成常驻进程php扩展库引入 composer.json{ "require": { "elasticsearch/elasticsearch": "~6.0" } }Client使用示例:prepare($sql); $query->execute(); $lists = $query->fetchAll(); print_r($lists); } catch (Exception $e) { echo $e->getMessage(); } $client = ClientBuilder::create()->build(); foreach ($lists as $row) { $params = [ 'body' => [ 'id' => $row['id'], 'title' => $row['title'], 'content' => $row['content'] ], 'id' => 'article_' . $row['id'], 'index' => 'articles_index', 'type' => 'articles_type' ]; $client->index($params); } } /* * 功能:获取索引 * return */ public function getIndex(){ $client = ClientBuilder::create()->build(); $params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'article_1' ]; $res = $client->get($params); print_r($res); } /* * 功能:从索引中删除文档 * return */ public function delIndex(){ $client = ClientBuilder::create()->build(); $params = [ 'index' => 'articles_index', 'type' => 'articles_type', 'id' => 'article_1' ]; $res = $client->delete($params); print_r($res); } /* * 功能:设置索引 * return */ public function createIndex(){ $client = ClientBuilder::create()->build(); $params['index'] = 'articles_index'; $params['body']['settings']['number_of_shards'] = 2; $params['body']['settings']['number_of_replicas'] = 0; $client->indices()->create($params); } /* * 功能:查询条件 * return */ public function search(){ $client = ClientBuilder::create()->build(); $params = [ 'index' => 'articles_index', 'type' => 'articles_type', ]; //多字段匹配 // $params['body']['query']['multi_match']['query'] = '我的宝马发动机多少'; // $params['body']['query']['multi_match']['fields'] = ["title","content"]; // $params['body']['query']['multi_match']['type'] ="most_fields"; // most_fields 多字段匹配度更高 best_fields 完全匹配占比更高 // // //单个字段匹配 // $params['body']['query']['match']['content'] = '我的宝马多少马力'; //完全匹配 // $params['body']['query']['match_phrase']['content'] = '我的宝马多少马力'; //联合搜索 must,should,must_not $params['body']['query']["bool"]['must']["match"]['content'] = "宝马"; $params['body']['query']["bool"]['must_not']["match"]['title'] = "宝马"; $res = $client->search($params); print_r($res); } } -
MYSQL数据表设计及使用规范 实际工作中数据库设计需要注意的具体操作问题。表设计1.库名、表名、字段名必须使用小写字母,“_”分割,且名称长度不超过12个字符并且要做到见名知意。2.建议使用InnoDB存储引擎。3.存储精确浮点数必须使用DECIMAL替代FLOAT和DOUBLE。4.建议使用UNSIGNED存储非负数值。5.建议使用INT UNSIGNED存储IPV4。6.整形定义中不添加长度,比如使用INT,而不是INT(4)。7.使用短数据类型,比如取值范围为0-80时,使用TINYINT UNSIGNED。8.不建议使用ENUM类型,使用TINYINT来代替。9.尽可能不使用TEXT、BLOB类型。VARCHAR(N),N表示的是字符数不是字节数,比如VARCHAR(255),可以最大可存储255个汉字,需要根据实际的宽度来选择N。10.VARCHAR(N),N尽可能小,因为MySQL一个表中所有的VARCHAR字段最大长度是65535个字节,进行排序和创建临时表一类的内存操作时,会使用N的长度申请内存。11.表字符集选择UTF8。12.使用VARBINARY存储变长字符串。13.存储年使用YEAR类型,存储日期使用DATE类型,存储时间(精确到秒)建议使用TIMESTAMP类型,因为TIMESTAMP使用4字节,DATETIME使用8个字节。14.建议字段定义为NOT NULL。15.将过大字段拆分到其他表中。16.禁止在数据库中使用VARBINARY、BLOB存储图片、文件等。索引1.索引名称必须使用小写,非唯一索引必须按照“idx_字段名称_字段名称[_字段名]”进行命名,唯一索引必须按照“uniq_字段名称_字段名称[_字段名]”进行命名。2.索引中的字段数建议不超过5个。3.单张表的索引数量控制在5个以内。4.唯一键由3个以下字段组成,并且字段都是整形时,使用唯一键作为主键。5.没有唯一键或者唯一键不符合4中的条件时,使用自增(或者通过发号器获取)id作为主键。6.唯一键不和主键重复。7.索引字段的顺序需要考虑字段值去重之后的个数,个数多的放在前面。8.ORDER BY,GROUP BY,DISTINCT的字段需要添加在索引的后面。9.使用EXPLAIN判断SQL语句是否合理使用索引,尽量避免extra列出现:Using File Sort,UsingTemporary。10.UPDATE、DELETE语句需要根据WHERE条件添加索引。11.不建议使用%前缀模糊查询,例如LIKE “%weibo”。12.对长度过长的VARCHAR字段建立索引时,添加crc32或者MD5 Hash字段,对Hash字段建立索引。13.合理创建联合索引(避免冗余),(a,b,c)相当于 (a) 、(a,b) 、(a,b,c)。14.合理利用覆盖索引。15.SQL变更需要确认索引是否需要变更并通知DBA。SQL语句1.SQL语句中IN包含的值不应过多。2.UPDATE、DELETE语句不使用LIMIT。3.WHERE条件中必须使用合适的类型,避免MySQL进行隐式类型转化。4.SELECT语句只获取需要的字段。5.SELECT、INSERT语句必须显式的指明字段名称,不使用SELECT *,不使用INSERTINTO table。6.使用SELECT column_name1, column_name2 FROM table WHERE[condition]而不是SELECT column_name1 FROM table WHERE[condition]和SELECT column_name2 FROM table WHERE [condition]。7.WHERE条件中的非等值条件(IN、BETWEEN、<、8.避免在SQL语句进行数学运算或者函数运算,容易将业务逻辑和DB耦合在一起。9.INSERT语句使用batch提交(INSERT INTO tableVALUES,,……),values的个数不应过多。10.避免使用存储过程、触发器、函数等,容易将业务逻辑和DB耦合在一起,并且MySQL的存储过程、触发器、函数中存在一定的bug。11.避免使用JOIN。12.使用合理的SQL语句减少与数据库的交互次数。13.不使用ORDER BY RAND,使用其他方法替换。14.建议使用合理的分页方式以提高分页的效率。15.统计表中记录数时使用COUNT(*),而不是COUNT(primary_key)和COUNT(1)。16.禁止在从库上执行后台管理和统计类型功能的QUERY。散表1.每张表数据量建议控制在5000w以下。2.可以结合使用hash、range、lookup table进行散表。3.散表如果使用md5(或者类似的hash算法)进行散表,表名后缀使用16进制,比如user_ff。4.推荐使用CRC32求余(或者类似的算术算法)进行散表,表名后缀使用数字,数字必须从0开始并等宽,比如散100张表,后缀从00-99。5.使用时间散表,表名后缀必须使用特定格式,比如按日散表user_20110209、按月散表user_201102。
-
MYSQL读写分离之--MYSQL主从复制、主主复制、双主多从配置 MySQL 主从复制原理: 从库生成两个线程,一个I/O线程,一个SQL线程; i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中; 主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog; SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;MySQL 主从复制主要用途:1.读写分离 在开发工作中,有时候会遇见某个sql 语句需要锁表,导致暂时不能使用读的服务,这样就会影响现有业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。2.数据实时备份,当系统中某个节点发生故障时,可以方便的故障切换一、如何配置MYSQL的主从复制?1. 两台数据库服务器,IP分别为 192.168.216.128 和 192.168.216.129,在服务器上装MYSQL(我的配置版本为5.5.56)2. 打开 192.168.216.128 服务器上的MYSQL的配置文件 /etc/my.cnf (路径根据自己服务器的情况来看),将其中的 server-id 设为1(默认为1,总之两台服务器要设置为不同的ID),然后重启MYSQL服务3. 打开 192.168.216.129 服务器上的MYSQL的配置文件 /etc/my.cnf (路径根据自己服务器的情况来看),将其中的 server-id 设为2(默认为1),然后重启MYSQL服务4. 设 192.168.216.128 为主服务器,那么在主服务器上加一个从服务器可以登录的用户,语句如下:1GRANT REPLICATION SLAVE ON *.* TO 'sally'@'192.168.216.129' IDENTIFIED BY 'ilovesally';FLUSH PRIVILEGES 建好后,在192.168.216.129 服务器上执行以下语句1mysql -h 192.168.216.128 -usally -pilovesally 然后试一下可不可以连上,如果可以,则正确,如果连不上,看一下什么原因,是否是防火墙的原因,如果是则去配置防火墙的规则。5. 以上完成后在主服务器上执行以下语句,查询master的状态show master status; 可以看到以上结果,这儿只需要看 File 和 Position,其它的两个分别是白名单和黑名单,意思为同步哪几个数据库和不同步哪几个数据库,可自行根据需求进行设置。记录了前两个字段后,在从库上执行以下语句:CHANGE MASTER TO MASTER_HOST='192.168.216.128', MASTER_USER='sally', MASTER_PASSWORD='ilovesally', MASTER_LOG_FILE='mysql-bin.000020', MASTER_LOG_POS=1441;6. 执行完毕后,在从库上继续执行如下语句:slave start; show slave status\G; 这样,查看从服务器的状态,如果状态中的用红线标出来两个参数的值都为YES,那证明配置已经成功,否则可以检查一下具体问题出现在什么地方。 这样,就算配置完成了。在主库中新建数据库,新建一张表,插几条数据,到从库上查询一下看是否已经同步过来。 如果失败,可以从以下几个方面去排查问题:1.首先试一下主从服务器相互之间是否 PING 得通2.试一下远程连接是否正确,如果连不上,则有可能是网卡不一致、防火墙没有放行 3306 端口3.server-id 是否配成一致4.bin-log 的信息是否正确 二、如何配置MYSQL的主主复制? 上面说了主从复制的配置方法,现在接着上面的配置继续,然后实现双主复制,让以上的两个服务器互为主从。1. 在主服务器上配置 /etc/my.cnf 文件,配置如下:auto_increment_increment=2 #步进值auto_imcrement。一般有n台主MySQL就填n auto_increment_offset=1 #起始值。一般填第n台主MySQL。此时为第一台主MySQL binlog-ignore=mysql #忽略mysql库【我一般都不写】 binlog-ignore=information_schema #忽略information_schema库【我一般都不写】 配置之后重启MYSQL服务2.在从服务器上配置 /etc/my.cnf 文件,配置如下auto_increment_increment=2 #步进值auto_imcrement。一般有n台主MySQL就填n auto_increment_offset=2 #起始值。一般填第n台主MySQL。此时为第二台主MySQL binlog-ignore=mysql #忽略mysql库【我一般都不写】 binlog-ignore=information_schema #忽略information_schema库【我一般都不写】 配置之后重启MYSQL服务3. 在从服务器上添加一个主服务器可以访问的用户,命令如下:GRANT REPLICATION SLAVE ON *.* TO 'sally1'@'192.168.216.128' IDENTIFIED BY 'ilovesally'; FLUSH PRIVILEGES 建好后,在192.168.216.128 服务器上执行以下语句mysql -h 192.168.216.129 -usally1 -pilovesally 如果可以连上,则进行下一步,连不上的话,参考上面进行问题排查。4. 因为要互为主从,所以现在从服务器也是master ,所以也要查看一下状态show master status; 查到相应的信息后,在原来的主服务器上执行以下命令(因为现在它现在也是另一台的从服务器)CHANGE MASTER TO MASTER_HOST='192.168.216.129', MASTER_USER='sally1', MASTER_PASSWORD='ilovesally', MASTER_LOG_FILE='mysql-bin.000021', MASTER_LOG_POS=1457;5. 执行完毕后,在原主库上继续执行如下语句:start slave; show slave status\G; 同上,如果出现如下画面,则证明配置成功。6. 在两台服务器的MYSQL中分别进行一些建库、建表、插入、更新等操作,看一下另一台会不会进行同步,如果可以则证明主主配置成功,否则还是上面的排错方法,进行错误排查。 三、如何配置MYSQL的双主多从? 现在已经是双主配置了,但是如果要进行读写分离,那么我们要再增加N台从库,如何做呢?非常简单,按如下操作即可:新增加一台数据库服务器,192.168.216.130,数据库配置均与前两台相同2. 确定一下要将哪一台当作自己的主服务器,我们姑且设 192.168.216.128 为主服务器3. 在第三台服务器中编辑 /etc/my.cnf ,将其 server-id 设为 3(保证与前两个不一样即可),然后重启MYSQL服务4. 在主服务器中,增加一条用户记录,用于当前服务器对主库对的连接,代码如下:GRANT REPLICATION SLAVE ON *.* TO 'farrow'@'192.168.216.130' IDENTIFIED BY 'ilovesally'; FLUSH PRIVILEGES;5. 在 192.168.216.130 服务器上测试是否可以连接到主库mysql -h 192.168.216.130 -ufarrow -pilovesally 如果可以连上,则可以进行下一步,否则根据上面的提示排查问题。6. 在 192.168.216.130 服务器上查询 master 当前状态 看到相关信息后,我们执行如下操作:CHANGE MASTER TO MASTER_HOST='192.168.216.128', MASTER_USER='sally', MASTER_PASSWORD='ilovesally', MASTER_LOG_FILE='mysql-bin.000020', MASTER_LOG_POS=1441;7. 执行完毕后,我们查询一下当前服务器的状态start slave; show slave status; 如果状态如下,则说明配置正确 如果此处有问题,参考上面所提排查并解决问题。8. 此时我们在 192.168.216.128 上建库、建表、插入、更新、删除数据,在 另外两台上分别进行查看,发现均已经同步。但是如果我们在 192.168.216.129 上做相应的操作,则发现只有 192.168.216.128 上进行了相应的同步,而 192.168.216.130 上的数据并未同步。这是为什么呢?因为我们设置的主库是 192.168.216.128,所以在 192.168.216.129 进行数据操作的时候并未同步,这显然不符合我们的需求,那么,我们要怎么修改呢?非常简单,在互为主从的两台服务器的配置文件中均加入以下语句:log-slave-updates=on 加上后将两台服务器的MYSQL重启,然后再进行测试,发现数据已经可以同步了。如果要再多加一些从服务器,和以上类似,现在我们做的是双主一从,我们可以再加N台从服务器,配置也是一样的。 至此,MYSQL主从复制、主主复制、双主多从配置我们均已经搞定。 Mysql 主从复制是mysql 高可用,高性能的基础,有了这个基础,mysql 的部署会变得简单、灵活并且具有多样性,从而可以根据不同的业务场景做出灵活的调整。
-
-